この記事では、Power Automate for Desktop(以下:PAD)のアクション、[Microsoft コグニティブ]グループの[Computer Vision]グループの中にあるアクションについて試してみましたのでそれぞれの役割や使用方法について初心者向けに解説したいと思います。
ぽこがみさま
PADならノンプログラマーでも画像解析できるよ!
Computer Visionとは、画像解析用のAIを用いたMicrosoftのサービスです。
この記事でやること
Power Automate for DesktopのMicrosoft コグニティブグループの中にあるアクションを使うためのAzure登録方法の解説
Power Automate for DesktopのComputer Visionグループの中にあるアクションの概要の解説
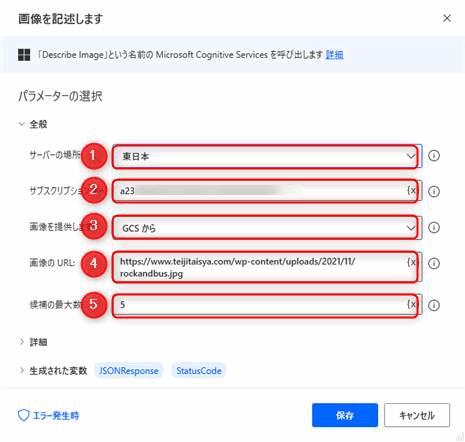
Power Automate for Desktopの「画像を記述します」アクションの使い方
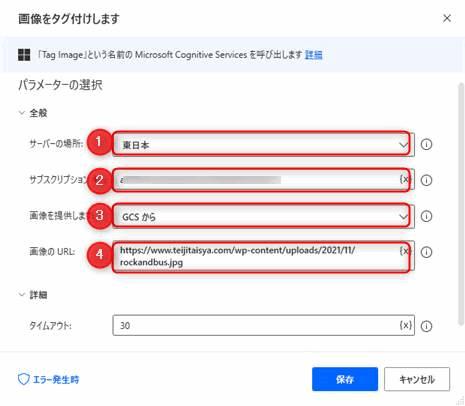
Power Automate for Desktopの「画像をタグ付けします」アクションの使い方
画像解析をするための前提条件
Microsoft コグニティブグループをアクションを利用するためにMicrosoft Azureの利用登録が必要です
Power Automate for Desktopで、Computer Visionを使ったアクションは、「Microsoftコグニティブ」の中に位置しています。これらのアクションを利用するには、Microsoft Azureの利用登録とアプリケーションの作成が必要です。下記の記事で利用登録の方法について解説していますのでAzure利用登録をされていない方はご覧ください。アプリケーションの作成後にサブスクリプションキーが発行されます。キーはPADのフロー作成の時に必要になりますのでメモ帳などにコピーしておいてくださいね。
Microsoft Azureは無料枠の範囲で無料試用することができます。この記事でも無料枠を使ってフローを作成します。
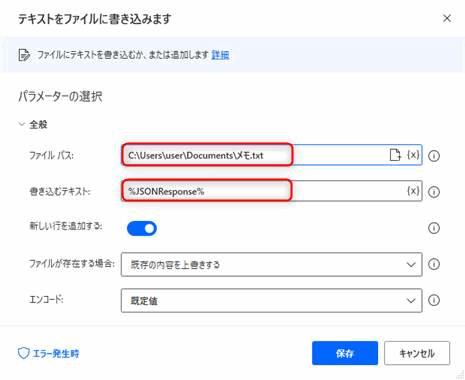
{
"description": {
"tags": [
"outdoor",
"mountain",
"rock",
"nature",
"building",
"rocky",
"stone",
"front",
"motorcycle",
"walking",
"side",
"desert",
"street",
"road",
"driving",
"man",
"old",
"dirt",
"traveling",
"brick",
"riding",
"stop",
"parked",
"hill",
"track",
"sign",
"standing",
"bus"
],
"captions": [
{
"Properties": {
"text": "a stone building with Arches National Park in the background",
"confidence": 0.948075120322047
}
},
{
"Properties": {
"text": "a stone building with Arches National Park in the desert",
"confidence": 0.947075120322047
}
},
{
"Properties": {
"text": "a close up of a stone building with Arches National Park in the background",
"confidence": 0.927155835294065
}
},
{
"Properties": {
"text": "Arches National Park with a mountain in the desert",
"confidence": 0.926155835294065
}
},
{
"Properties": {
"text": "a close up of a stone building with Arches National Park in the desert",
"confidence": 0.925155835294065
}
}
]
},
"requestId": "35d458ac-f0d3-4305-b29a-8e1f47425796",
"metadata": {
"height": 396.0,
"width": 560.0,
"format": "Jpeg"
}
}
"captions": [
{
"Properties": {
"text": "a stone building with Arches National Park in the background",
"confidence": 0.948075120322047
}
},
{
"Properties": {
"text": "a stone building with Arches National Park in the desert",
"confidence": 0.947075120322047
}
},
省略
]
文章は現在のところ英語のみ対応しているようです。
”a close up of a stone building with Arches National Park in the background”
“a stone building with Arches National Park in the desert”


 ぽこがみさま
ぽこがみさま

 じょじお
じょじお