ガチなシャツ
リライブシャツすごすぎワロタwwwwww【リライブシャツを買ってみたらガチだった。】 リライブシャツ 着るだけで「身体機能をサポートする」怪しいシャツがガチだった。 YouTubeやSNSでバズってた「リライブ...

この記事でわかること!
 じょじお
じょじお以前、「Google Colaboratoryを使ってクラウド上にPython環境を簡単に用意する」という内容の記事を書きました。
 ぽこがみさま
ぽこがみさま今回はGoogle Colaboratoryでスクレイピングして外部のWebページの情報を取得する方法について紹介したいと思います。

Google Colaboratoryは、Googleアカウントさえあれば無料で利用できます。
クラウド上に環境を構築するのでどのPCからアクセスしても同じ環境でPythonを実行したり・スクリプトの作成を再開したりすることができます。
Google ColaboratoryはGoogeドライブとの連携が簡単です。スクレイピングの結果をGooge ドライブに出力して見易い形で表示することも簡単です。
Google Colaboratoryには、定期実行やイベントを待機してトリガー実行する仕組みはありません。作成したPythonスクリプトの開始は手動で行うことになります。このため自動でスクリプトを動かしたい場合は、自分のパソコンに環境を構築するか、GCP・AWS・Azure・Herokuなどのクラウドサービスを利用する必要があります。
Google Coraboratoryに自分で追加したPythonモジュールはセッションが切れると削除されます。例えば、Google CoraboratoryにデフォルトではインストールされていないSeleniumモジュールを使うPythonスクリプトを作成して次の日にもう一度実行しようとするとき、再びSeleniumのインストールが必要です。とはいえ、ColabファイルにSeleniumインストールコマンドの記述を残しておけばそれを実行するだけなので大きな手間ではないかなと思います。
ぽこがみさまPythonにはスクレイピングするためによく使われる3つのライブラリがあります。
| requests | Beautiful soup | Selenium | |
|---|---|---|---|
| 特徴 | 指定したURLに対してリクエストを投げてレスポンスを取得します。 | HTMLやXMLを解析(パース)してデータを抽出します。 | ブラウザの動作をエミュレートしてHTMLを取得します。 |
| HTMLの取得 | 〇 | × | 〇 |
| HTMLの解析 | × | 〇 | 〇 |
| 静的ページ | 〇 | – | 〇 |
| 動的ページ | × | – | 〇 |
| ログインが必要なWebページのスクレイピング | × | – | 〇 |
スクレイピングをするとき、Webページを静的ページと動的ページの2つに分類して語られることが多くあります。
Webサーバにリクエストして、ブラウザが受け取った情報を、そのままブラウザ上に表示するページです。
Webサーバにリクエストして、ブラウザが受け取った情報を、JavaScriptで動的に変更してから表示するページです。
じょじおJavaScriptはブラウザ上で動作するのでJavaScriptを使ったWebページのスクレイピングを正確に行うには、ブラウザの動作をエミュレートできる機能をもったライブラリが必要です。
ぽこがみさまJavascriptが使われている動的ページをスクレイピングできるライブラリにはSeleniumやpyppeteerがあります。
requestsは、指定したURLに対してリクエストを投げてレスポンスを取得するライブラリです。もっとも基本的でシンプルかつ高速なのでよく利用されます。HTMLをただ取得するだけでデータ抽出は得意ではありません。このためデータ抽出が得意なbeautiful soupとセットでよく利用されます。また、ブラウザをエミュレートする機能はないため動的ページの情報を取得することはできません。
Beautiful soupは、HTMLやXMLを解析(パース)してデータを抽出するライブラリです。ページ情報の取得は行えないためrequestsとあわせて使われることが多いです。
Seleniumは、ブラウザの動作をエミュレートしてHTMLを取得するライブラリです。ヘッドレスブラウザ(バックグラウンドで動くブラウザ)を使うことができるので動的のページの情報を取得することができます。高機能な分、requestsと比較すると動作は遅いです。
ヘッドレスブラウザを扱うことができるライブラリは他にもpyppeteerがあります。こちらも人気のライブラリです。ほとんどできることは同じなので好きなほうを選べばいいかなと思います。
静的ページをスクレイピングする時のもっとも一般的なアプローチの方法は、beautiful Soupを使う方法です。beautiful Soupは解析するためのライブラリで、HTMLの取得はできないので、HTMLの取得ができるrequestsと組み合わせて使われることが多いです。
じょじおまずは静的ページのスクレイピングするスクリプトについて紹介します。
import requests
from bs4 import BeautifulSoup
# ターゲットWebページのURLを指定します。
url = "https://www.teijitaisya.com/"
# htmlを取得します。
html = requests.get(url)
# 取得したHTMLをBeautifulSoupを使ってパースします。
soup = BeautifulSoup(html.content, "html.parser")
# パースしたHTMLから特定の要素を抽出します。結果はリストで返ってきます。
elem = soup.select("a")
# 抽出した要素ひとつひとつから情報を取得します。
for e in elem:
print (e.attrs["href"])
▲簡単な静的ページのスクリプトの例です。
import requests from bs4 import BeautifulSoup
▲requestsとbeautifulSoupをインポートします。
# ターゲットWebページのURLを指定します。 url = "https://www.teijitaisya.com/" # htmlを取得します。 html = requests.get(url)
▲requests.get()を使ってHTMLを取得します。
# 取得したHTMLをBeautifulSoupを使ってパースします。 soup = BeautifulSoup(html.content, "html.parser")
▲requestsは詳しい解析はできないのでbeautiful Soupを使ってHTMLのタグ名やクラス名を認識します。
print(soup)

▲解析したsoup変数をprint関数でみてみると、HTMLが確認できます。ご覧いただいてわかるようにここで取得できるのはHTMLそのものなので、次のステップでBeautiful Soupの機能を使ってもう少し細かくデータを切り出してみたいと思います。
# パースしたHTMLから特定の要素を抽出します。結果はリストで返ってきます。
elem = soup.select("a")
▲例として先ほど取得したHTMLからすべてのaタグ要素を取得してみたいと思います。selectメソッドの引数はCSSセレクタを渡すことができます。戻り値はリストです。
print(elem[0]) # 実行結果 >>> <a href="https://www.teijitaisya.com/category/office/">Microsoft<span class="c-submenuToggleBtn" data-onclick="toggleSubmenu"></span></a>
▲elem[0]をprintしてリストの1つ目のデータを見てみると、HTMLのaタグの要素をまるっと取得できていることがわかります。
# 抽出した要素ひとつひとつから情報を取得します。 for e in elem: print (e.attrs["href"])
▲先ほどのステップでHTMLからaタグ要素を抽出することができました。しかし、先ほどの取得したのはタグを含んだ要素なのでデータとしては扱いづらいです。Beautiful Soupではもう少し細かく情報を抽出することができます。例えば上の例はhref属性にセットされたURLを取得しています。
| よく使うメソッド | 説明 |
|---|---|
| attrs[“属性名”] | 要素から属性のバリューを抽出します。 |
| get_text() | 要素からテキストを抽出します。 |
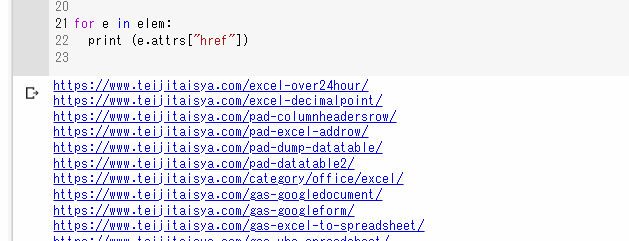
▲実行結果です。ページ内のaタグのhrefにセットされたURLの一覧を取得することができました。
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
じょじお続いてSeleniumでスクレイピングするときの基本的なスクリプトについて解説します。
ぽこがみさま下記はページ内のすべてのリンクのURLを取得するときのコードサンプルです。
from selenium import webdriver
from selenium.webdriver.common.by import By
# 出力先フォルダ
filepath = "drive/MyDrive"
# ターゲットURL
URL = "https://www.teijitaisya.com/"
# Chrome Driverにセットするオプションの設定。
# やっとかないとエラーになるよ!
options = webdriver.ChromeOptions()
options.add_argument('--headless') # ヘッドレスモードを有効にする。
options.add_argument('--no-sandbox') # sandboxモードを解除する。この記述がないとエラーになってしまう。
options.add_argument('--disable-dev-shm-usage') # /dev/shmパーティションの使用を禁止し、パーティションが小さすぎることによる、クラッシュを回避する。
# Webドライバーをセット
driver = webdriver.Chrome('chromedriver',options=options)
# URLにpostしてページ情報を取得する
driver.get(URL)
driver.implicitly_wait(10) #暗黙の待機
# 要素をまとめてリストとして取得
results = driver.find_elements(By.TAG_NAME,"a")
# リストから要素をひとつひとつ取り出し、そこからhref属性を抽出する。
for r in results:
print(r.get_attribute("href"))
# ブラウザーを終了します。
driver.quit()
Google Colabは、Seleniumがデフォルトでインストールされていないため、スクリプトを書く前にSeleniumをインストールします。pipコマンドでインストールを行います。Google Colabでコマンドを実行するときは下記のようにコマンドの先頭に「!(エクスクラメーション)」をつけます。
!pip install selenium
▲コマンドを実行して、InstalledとかSuccessとかのそれっぽいメッセージが表示されれば成功です。
Seleniumでブラウザをエミュレートさせるにはブラウザのドライバをインストールします。今回はGoogle Chromeベースのchromium-chromedriverを使用します。
Google Colaboratoryは、デフォルトではchromium-chromedriverがインストールされていないため下記のLinuxコマンドでインストールを行います。インストールしたらドライバファイルをわかりやすい場所/usr/binにコピーします。
!apt-get update !apt install chromium-chromedriver !cp /usr/lib/chromium-browser/chromedriver /usr/bin

ここからスクリプトを書いていきます。まずはSeleniumからwebdriverとByをインポートします。
from selenium import webdriver from selenium.webdriver.common.by import By
ドライバを実行する前にドライバにセットするオプションの記述を行います。ここに書いているのは必要最低限なオプションでGoogle colabで実行する場合このオプションの記述がないとエラーになります。
# Chrome Driverにセットするオプションの設定。
# やっとかないとエラーになるよ!
options = webdriver.ChromeOptions()
options.add_argument('--headless') # ヘッドレスモードを有効にする。
options.add_argument('--no-sandbox') # sandboxモードを解除する。この記述がないとエラーになってしまう。
options.add_argument('--disable-dev-shm-usage') # /dev/shmパーティションの使用を禁止し、パーティションが小さすぎることによる、クラッシュを回避する。
# Webドライバーをセット
driver = webdriver.Chrome('chromedriver',options=options)
webdriver.Chome()を使ってChromeドライバのインスタンスを作成します。webdriver.Chome()の引数には、「ドライバファイルのパス名」と、上で作成した「ドライバーオプション」を渡します。
# ターゲットURL URL = "https://www.teijitaisya.com/" # URLにpostしてページ情報を取得する driver.get(URL)
driver.get(“ターゲットurl”)でターゲットページの情報を取得します。
Webページによっては、Ajaxの仕組みをつかってページがロードされてから画面を書き換えるといったことが行われています。書き換え後の完璧な情報を取得するために待機時間を入れて調整します。Seleniumは待機方法がいくつかありますがよく使うものを紹介します。
秒数を指定して待機する方法です。
#暗黙の待機(秒) driver.implicitly_wait(10)
指定した要素が出現するまで待機し続けます。ページに指定した要素がない場合に無限ループにならないように最大待機時間も設定します。
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver.get(URL)
# ページ内のすべての要素が読み込まれるまで待機します。10秒たったらタイムアウトにします。
element = WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located
)
| メソッド | 条件 |
|---|---|
| visibility_of_element_located | 指定した要素の表示される |
| text_to_be_present_in_element | 指定したテキストが表示される |
| presence_of_all_elements_located | ページ内のすべての要素が読み込まれる |
| presence_of_element_located | DOM要素内に指定した要素が現れる |
| alert_is_present | Alertが表示される |
| element_to_be_clickable | 要素がクリック出来る状態になる |
# タグ名で要素を取得する。 results = driver.find_elements(By.TAG_NAME,"a")
要素を取得するには、driver.find_elementsを使用します。Byクラスを使ってタグ・クラス・XPathなどを指定します。
| Byクラス | 特定方法 | 使用例 |
|---|---|---|
| By.CLASS_NAME | クラス属性 | #p-postList__titleというクラス名の要素を取得します。 results = driver.find_elements(By.CLASS_NAME, “p-postList__title”) |
| By.TAG_NAME | タグ名 | #aタグをすべて取得します。 results = driver.find_elements(By.TAG_NAME,”a”) |
| By.NAME | name属性 | username = driver.find_elements(By.NAME,”username”) password = driver.find_elements(By.NAME,”password”) |
| By.ID | id属性 | results = driver.find_elements(By.ID,”username”) |
| By.LINK_TEXT | リンクテキスト | results = driver.find_elements(By.LINK_TEXT,”詳細ページはこちらです”) |
| By.PARTICAL_LINK_TEXT | リンクテキストに含まれる一部の文字列 | results = driver.find_elements(By.PARTICAL_LINK_TEXT,”詳細ページ”) |
| By.XPATH | XPATH | login_form = driver.find_element_by_xpath(“/html/body/form[1]”) または、 login_form = driver.find_element_by_xpath(“//form[1]”) |
| By.CSS_SELECTOR | CSSセレクタ | results = driver.find_elements(By.CSS_SELECTOR,”p.content”) |
driver.find_elements()で取得した要素はリストで返却されます。ひとつひとつはWebElementクラスです。WebElementクラスから情報を取得するには下記のメソッド・プロパティを使います。
| WebElementクラスから情報を取得するためのメソッド・プロパティ | 説明 |
|---|---|
| get_attribute(“属性名”) | 指定された属性または要素のプロパティを取得します。 |
| text | 要素のテキストを取得します。 |
<html>
<!-- 前後省略 -->
<a href="https://www.teijitaisya.com">僕の一つ目のブログです。</a>
<a href="http://www.eigorou.com">僕の二つ目のブログです。</a>
<!-- 前後省略 -->
</html>
▲上記のサンプルHTMLを例に解説します。
# 要素のテキストを取得する。 results = driver.find_elements(By.TAG_NAME,"a") for r in results: print(r.text) ## 実行結果 >>> 僕の一つ目のブログです。 >>> 僕の二つ目のブログです。
▲先ほどのサンプル.htmlからaタグのテキストを抽出する例です。
# 要素のhref属性を取得する。
for r in results:
print(r.get_attribute("href"))
## 実行結果
>>> https://www.teijitaisya.com
>>> http://www.eigorou.com
▲先ほどのサンプル.htmlからaタグのhref属性のurlを抽出する例です。
# ブラウザーを終了する。 driver.quit()
▲最後にドライバーを閉じます。この記述を忘れるとSeleniumがメモリ上に常駐し続けてコンピュータに負荷がかかるので注意してください。
Selenium 日本語ドキュメント(非公式)
https://kurozumi.github.io/selenium-python/installation.html
Google Colaboratoryでスクレイピングするときは取得した情報をGoogle Driveに出力すると便利かなと思います。簡単な出力例を紹介します。

▲Google Driveと連携するには最初に簡単な設定が必要です。

▲Google Driveと連携する際のファイル・フォルダ操作のまとめです。


スクレイピングを行う際は、ターゲットとするWebページのHTML構造を分析して、目的の情報がどんなHTML要素に囲まれているかを知る必要があります。HTMLの分析にはブラウザの開発者ツールの機能を使うことが一般的です。下記の記事に開発者ツールの基本的な使い方をまとめました。

スクレイピングを行う際はルールとモラルを守って正しく行ってください。中にはスクレイピングを禁止するWebサイト・Webサービスもありますので事前に確認してください。
また、APIが公開されているWebサービスはスクレイピングではなくAPIを使って情報を取得した方がスマートに情報を取得できる場合が多いです。ターゲットとするWebサービスでAPIが提供されているかを確認して検討してください。
じょじおGoogle Colaboratoryを使ってpythonでスクレイピングする方法についてご紹介しました。
ぽこがみさまこのブログではRPA・ノーコードツール・VBA/GAS/Pythonを使った業務効率化などについて発信しています。
参考になりましたらブックマーク登録お願いします!
▲Python入門者向けの書籍です。デスクワークの業務効率化方面を中心に自動化するスクリプトを作成することができます。Excel・Word・PDF・デスクトップアプリ化・メールなどなど。身近な作業を自動化しながら学べるので事務員の方やエンジニアの方幅広くお勧めできます。
▲Pythonでデータ分析するのに超絶おすすめです。データ分析でよく使うPandasモジュールを中心にデータ加工から分析までの基礎を理解できます。
▲Pythonのお作法なんかが書かれています。
じょじおPythonを実践的に学ぶなら筆者も受講したデイトラがおすすめです。



