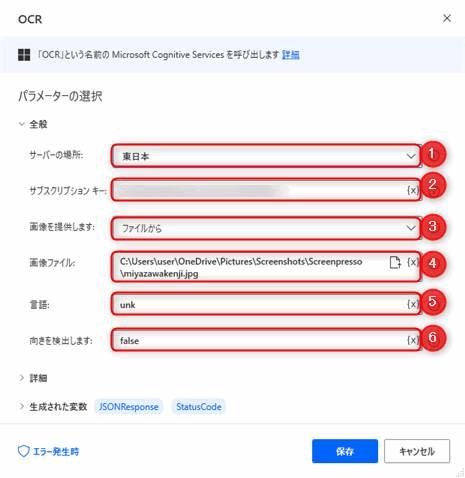
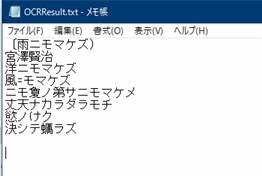
MicrosoftCognitive.OCRMicrosoft.OCRFromFile ServerLocation: Cognitive.MicrosoftServerLocation.JapanEast SubscriptionKey: $'''a239a8a1b404448ead7786d814dad835''' ImageFile: $'''C:\\Users\\user\\OneDrive\\Pictures\\Screenshots\\Screenpresso\\miyazawakenji.jpg''' Language: $'''unk''' DetectOrientation: $'''false''' Timeout: 30 Response=> JSONResponse StatusCode=> StatusCode
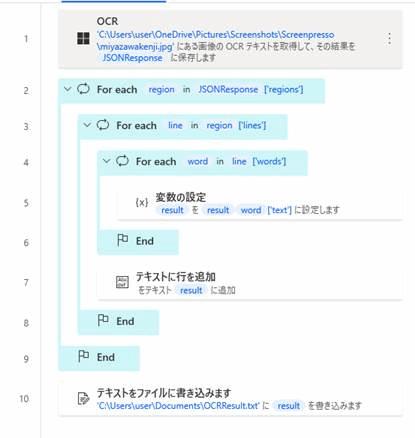
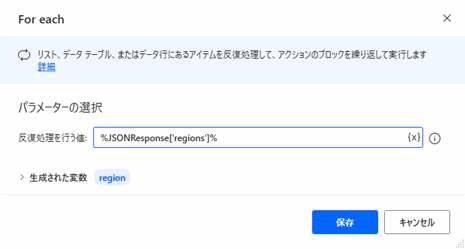
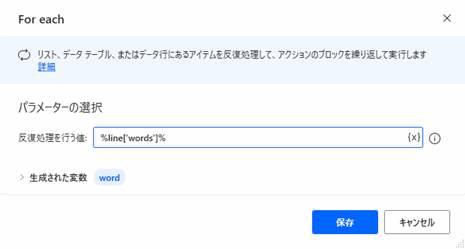
LOOP FOREACH region IN JSONResponse['regions']
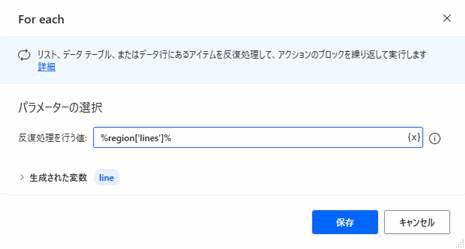
LOOP FOREACH line IN region['lines']
LOOP FOREACH word IN line['words']
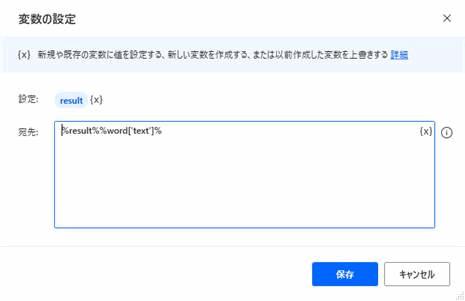
SET result TO $'''%result%%word['text']%'''
END
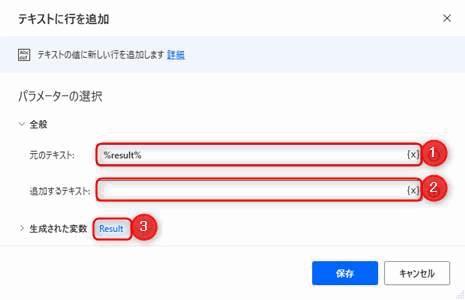
Text.AppendLine Text: result LineToAppend: $'''''' Result=> Result
END
END
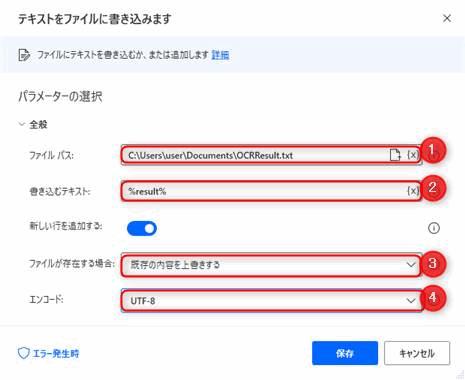
File.WriteText File: $'''C:\\Users\\user\\Documents\\OCRResult.txt''' TextToWrite: result AppendNewLine: True IfFileExists: File.IfFileExists.Overwrite Encoding: File.FileEncoding.DefaultEncoding






 じょじお
じょじお
