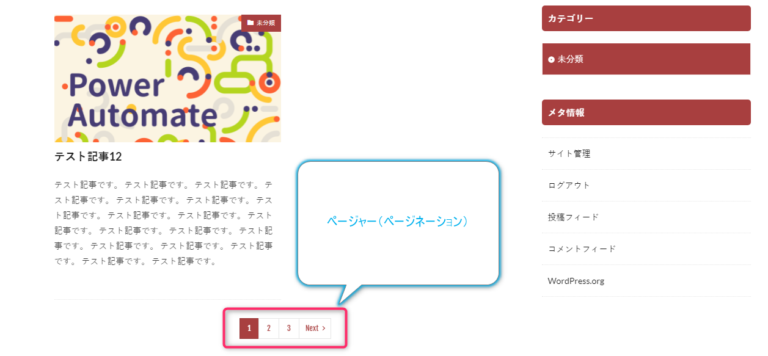
ガチなシャツ
リライブシャツすごすぎワロタwwwwww【リライブシャツを買ってみたらガチだった。】 リライブシャツ 着るだけで「身体機能をサポートする」怪しいシャツがガチだった。 YouTubeやSNSでバズってた「リライブ...

Power Automate Desktopを使って、複数ページにわたるWebサイトのデータを取得する方法について解説します。
 じょじお
じょじおPower Automate Desktopならページャーが使われたWebページでも無料で簡単に巡回できます。CSSやHTMLなどのWeb技術の知識も不要です。(Webサイトによります。)
一般公開されているWebサイトでも、自動でWebサイトの情報を取得することを禁止しているWebサイトもあります。
ご利用の際は、事前に各Webサイトのrobots.txtなどを確認して違反にならない範囲で活用してください!
この記事の内容は下記の条件で作成・検証を行っています。
拡張機能のインストール方法については前の記事を参考にしてみてください。

この記事で作成するフローの全体図です。

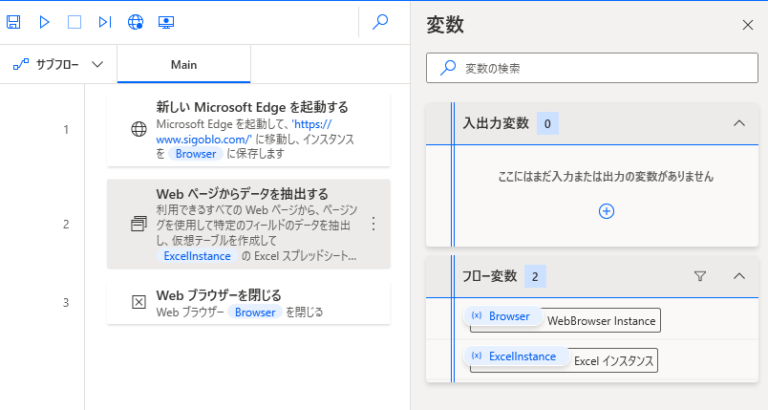
▼フローを作成します。
Power Automate Desktopを起動してフローを作成します。
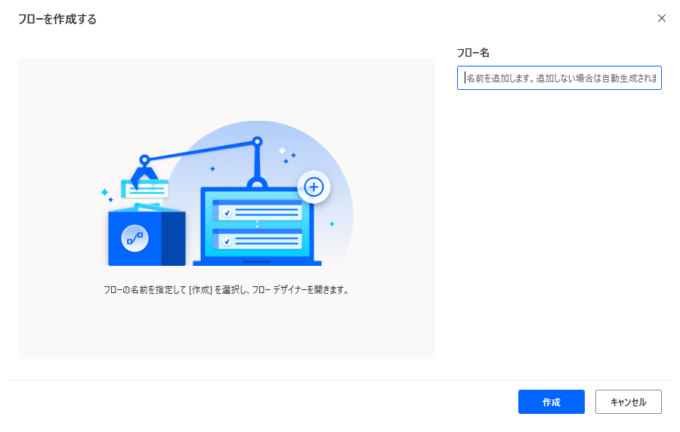
▼フロー名を入力し作成をクリックします。
▼「新しいMicrosoft Edgeを起動する」を追加します。
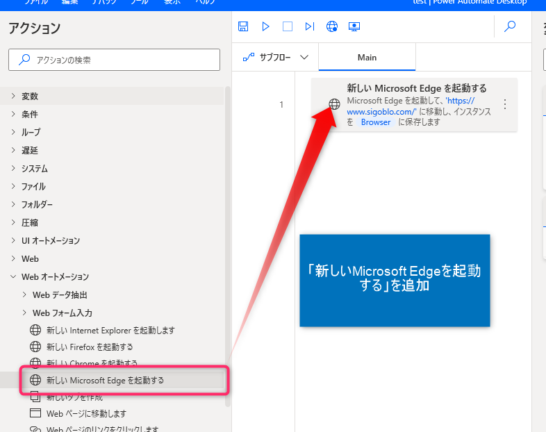
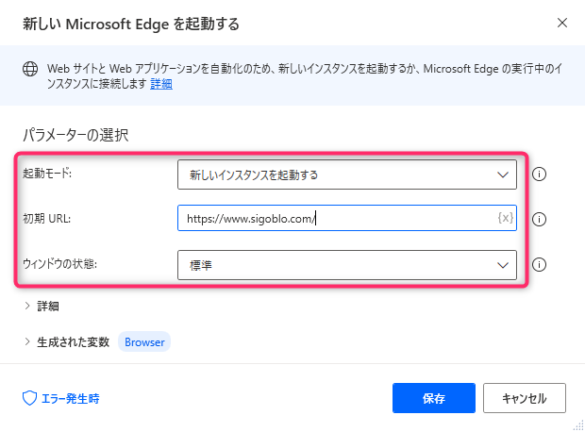
▼パラメータを入力します。
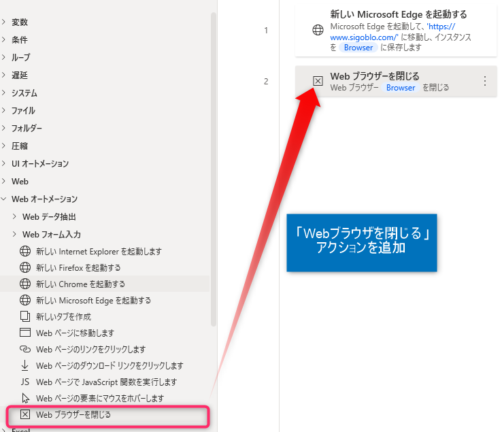
▼「Webブラウザを閉じる」アクションを追加します。
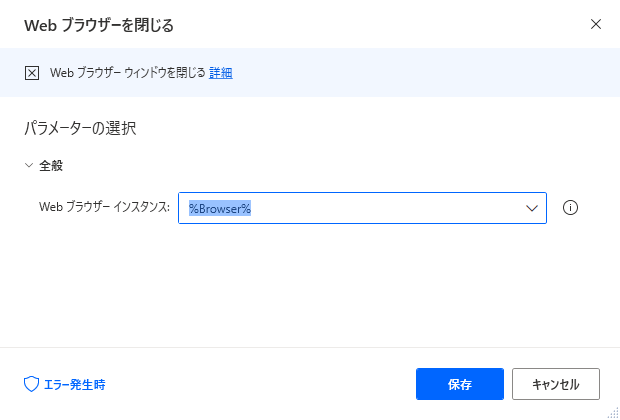
▼パラメータはデフォルトで入力された値「%Brouser%」のまま変更せずに保存をクリックします。
▼「アクションごとに実行」ボタンをクリックします。
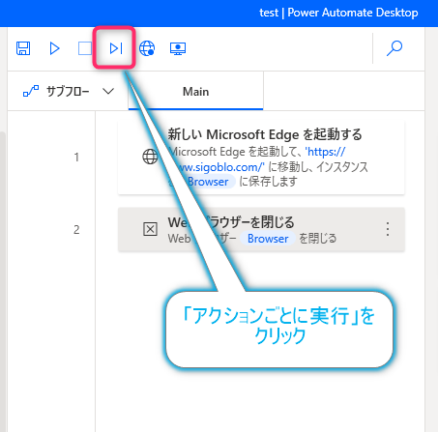
▼一番上のアクション「Microsoft Edgeを起動する」が実行されるので、この状態フローを停止させます。ブラウザは閉じないでください。
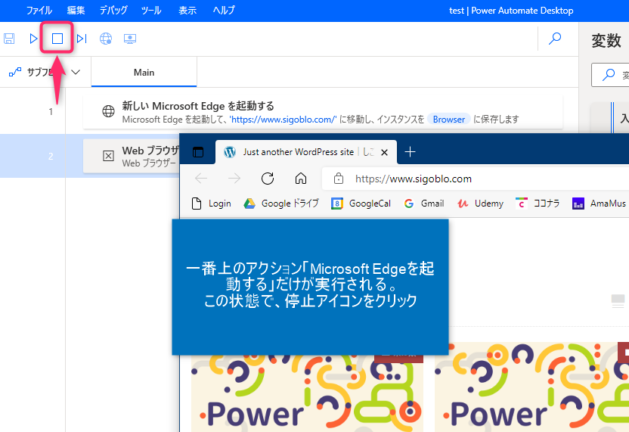
▼「Webページからデータを抽出する」アクションを「Microsoft Edgeを起動する」アクションのうしろに追加します。
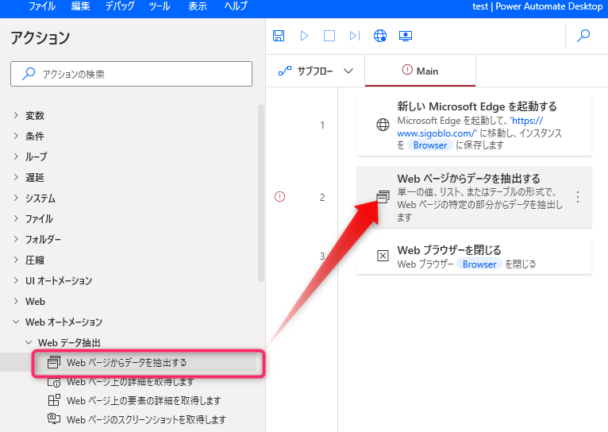
▼図の画面が表示されます。この画面を開いたまま先ほどフローが開いたブラウザに戻ります。
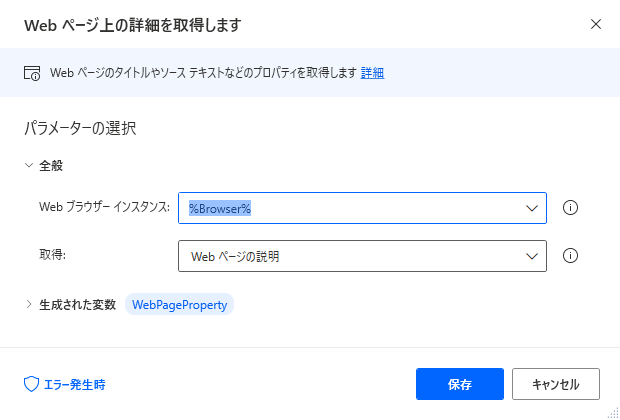
▼すると「ライブWebヘルパー」という画面が自動で開きます。
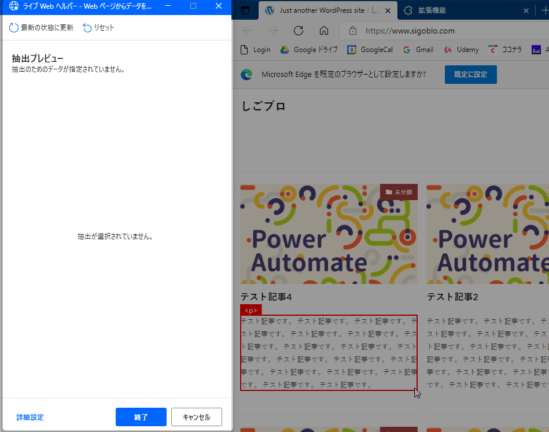
この画面に、ページのどこを抽出するかを記録していきます。以前の記事で紹介したWebレコーダーに似ていますね。
▼まずは記事タイトルを抽出する設定を行います。
記事を一つ選び、記事タイトルにマウスカーソルをあわせて右クリック→「要素の値を抽出」→「テキスト」をクリックします。
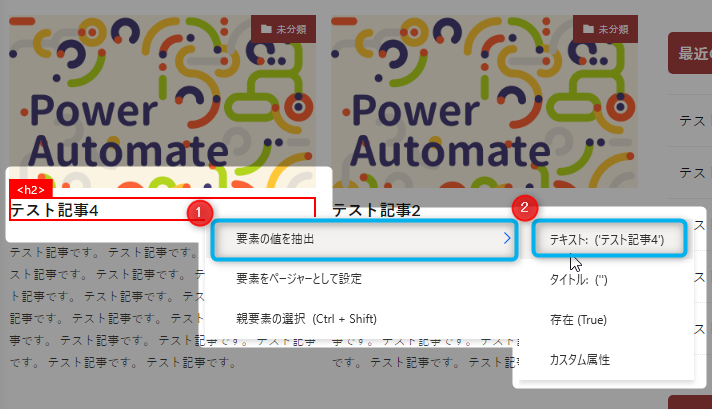
▼となりの記事も同様に抽出設定を行います。
▼ここで「ライブWebヘルパー」を見てみましょう。

2つの記事の情報を抽出しただけなのに、ページ内のすべての記事タイトルを認識してくれていますね!
じょじおこのように一定のルールで繰り返される要素は、2個だけ取得設定を行えば、同じ繰り返し要素をすべて取得できます。
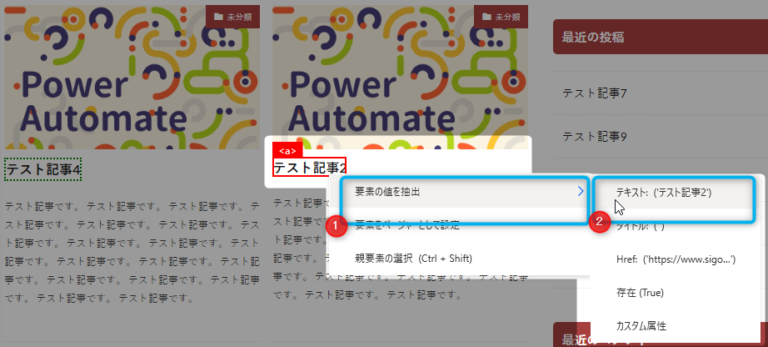
▼わたしは記事URLも欲しいので記事URLを取得していきます。

このWebサイトは記事タイトルのところが記事へのリンクになっているので、記事タイトルから抽出すればよさそうですね。記事タイトルを右クリック→要素の値を抽出→「Href」をクリックします。
▼まだ1個しかURLを抽出していませんが、ここでライブWebヘルパーを見てみましょう。
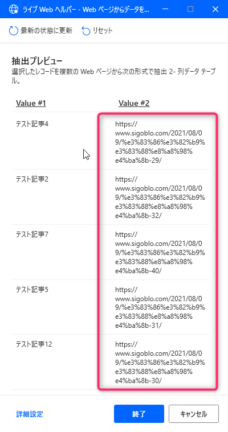
なんと1個しか抽出設定を行っていないのに、全部の記事URLを抽出対象にしてくれました。
そうなんです。2種類目の情報を取得するときは1回だけ設定すればいいんです。簡単ですね!
ここまでで1ページの記事情報はすべて抽出できました。このWebサイトは9ページあるので、残りのすべてのページの情報も抽出していきます。
じょじおこう聞くと不安になる方もいらっしゃると思いますが、安心してください。 PADならめちゃめちゃ簡単です。
▼ページャーの「Next」を右クリック→「ページャーとして設定」をクリックします。
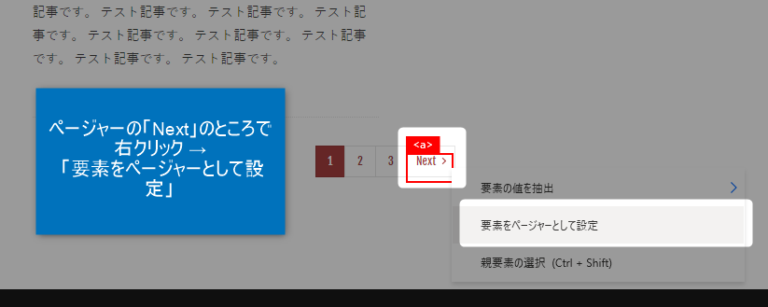
NextはWebサイトによって「次へ」だったり「>」だったりいろいろなUIデザインがあるかもしれません。Webページによって読み替えてください。
▼「ライブWebヘルパー」を確認します。
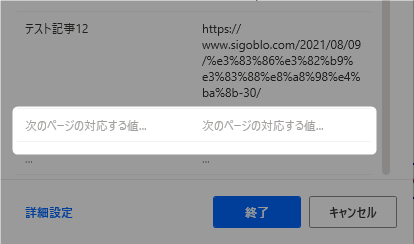
「次のページに対応する値」という文言が追加されていればOkです。
ページャーの設定はこれだけです。取得したい情報の設定がすべて完了しました。「ライブWebヘルパー」画面を終了ボタンをクリックして閉じてください。
▽「ライブWebヘルパー」画面を閉じると下図の「Webページからデータを抽出する」アクションの設定画面に戻るかと思います。
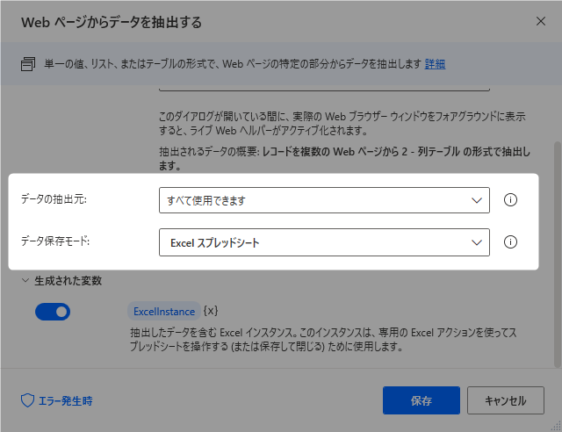
図の「Webページからデータを抽出する」画面が開いたままかと思います。パラメータを入力して保存します。
これでフローは完成しました。フローは保存して次項にてテストしてみましょう。
じょじおおつかれさまです!
以上でフローが完成しました。テストしてみましょう!
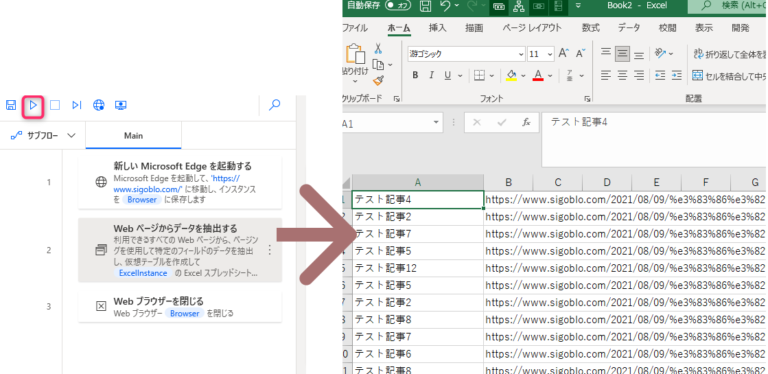
▲図のようにExcelが表示されました!
「UI要素が見つかりません」のエラーが発生する時やエラーでフローが正常に動作しない時は下記の記事を参考にUI要素を登録しなおすかセレクターを編集してみてください。
いかがでしたでしょうか。たった3つのアクションで複数ページのデータを抽出することができました。いろいろなWebサイト、社内システムで応用できるかと思いますので、是非試してみてください!
▲Kindleと紙媒体両方提供されています。デスクトップフロー、クラウドフロー両方の解説がある書籍です。解説の割合としてはデスクトップフロー7割・クラウドフロー3割程度の比率となっています。両者の概要をざっくり理解するのにオススメです。
▲Power Automate for Desktopの基本をしっかり学習するのにオススメです。この本の一番のメリットはデモWebシステム・デモ業務アプリを実際に使ってハンズオン形式で学習できる点です。本と同じシステム・アプリを使って学習できるので、本と自分の環境の違いによる「よく分からないエラー」で無駄に躓いて挫折してしまう可能性が低いです。この点でPower Automate for desktopの一冊目のテキストとしてオススメします。著者は日本屈指のRPAエンジニア集団である『ロボ研』さんです。
▲Power Automate クラウドフローの入門書です。初心者の方には図解も多く一番わかりやすいかと個人的に思っています。
Microsoft 365/ Power Automate / Power Platform / Google Apps Script…
▲Udemyで数少ないPower Automateクラウドフローを主題にした講座です。セール時は90%OFF(1200円~2000円弱)の価格になります。頻繁にセールを実施しているので絶対にセール時に購入してくださいね。満足がいかなければ返金保証制度がありますので安心してご購入いただけます。



