ガチなシャツ
リライブシャツすごすぎワロタwwwwww【リライブシャツを買ってみたらガチだった。】 リライブシャツ 着るだけで「身体機能をサポートする」怪しいシャツがガチだった。 YouTubeやSNSでバズってた「リライブ...

前回の記事で「OCRを使ってテキストを抽出」アクションを使ってPDFを全文抽出する方法についてお伝えしました。今回の記事ではPDFの文章の中の一部の文字列を抽出する部分抽出の方法について学習していこうと思います。
前回はアクションの動作を確認するための実験的な内容でしたが、今回ご紹介する方法は実用的な内容となっているかなと思います。よろしければ参考になさってください。

▲前回の記事をご覧いただいていない方はこちらからご覧いただいた方が分かりやすいかと思います。
前回の記事では、「OCRを使ってテキストを抽出」アクションを自分で追加して、自分でパラメータを入力しました。しかし、部分抽出の場合は、「1.アンカー領域となる画像の設定」と、「2.相対座標の設定」という2つの設定が必要になります。この2つのパラメータを自分で調整するのは難しいです。
そこで便利なのが、Power Automat for Desktopのデスクトップレコーダー機能です。デスクトップレコーダーは、「実際のパソコン操作」をコンピュータに見せると、操作をコンピュータが学習し、操作に見合ったアクションを自動作成してくれる機能です。今回はこの機能を使って楽ちんにアクションを作っていきましょう!
 ぽこがみさま
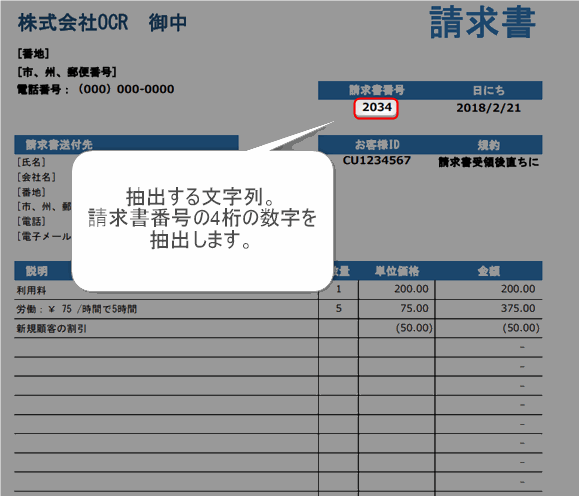
ぽこがみさま今回は、下図のPDFファイルから、請求書番号2034を抽出することをゴールとします!
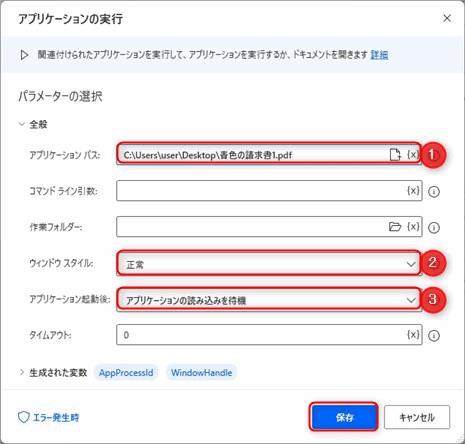
▲システムグループの中にある「アプリケーションの実行」アクションを追加します。下記のようにパラメータを入力します。
ウインドウサイズは最小や非表示にすると読み取りできません。文字を大きく表示した方が精度があがりそうなので全画面にしています。
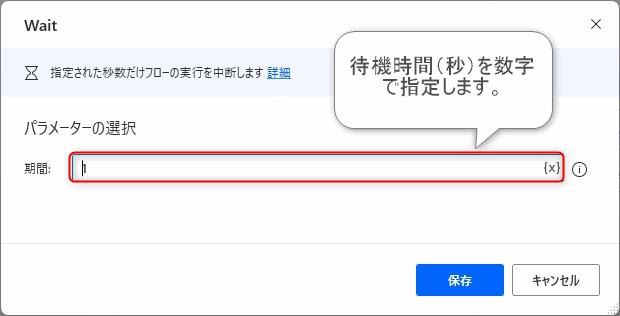
▲フローコントロールグループの中にある「Wait」アクションを追加します。
PDFアプリケーションが起動して完全にファイルが表示されることを待つために待機処理を入れます。今回は1秒待機するようにします。1と入力します。
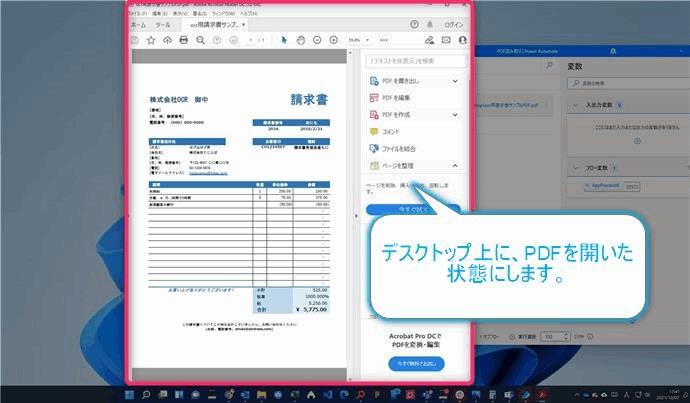
ここからデスクトップレコーダーを使ってアクションを追加していきますが、その前の準備としてPDFファイルを開いた状態にしたいので、一度アクションを実行してPDFファイルを開きます。上図のようにPDFファイルが開きましたらPADのフローデザイナーに戻ってください。
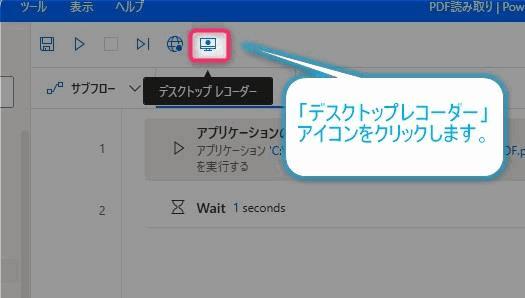
▲フローデザイナーの画面上部にある「デスクトップレコーダー」アイコンをクリックします。
▲「デスクトップレコーダー」アイコンをクリックすると図のような「デスクトップレコーダー」画面が起動します。
①デスクトップレコーダー画面右上の「画像記録」をオンしてから、②「レコード」をクリックしてレコードを開始します。
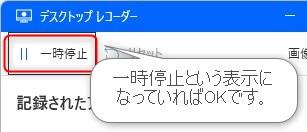
▲レコードが開始されると「レコード」という文言が「一時停止」という文言に変わります。「一時停止」という表示になっていることを確認して次に進みます。
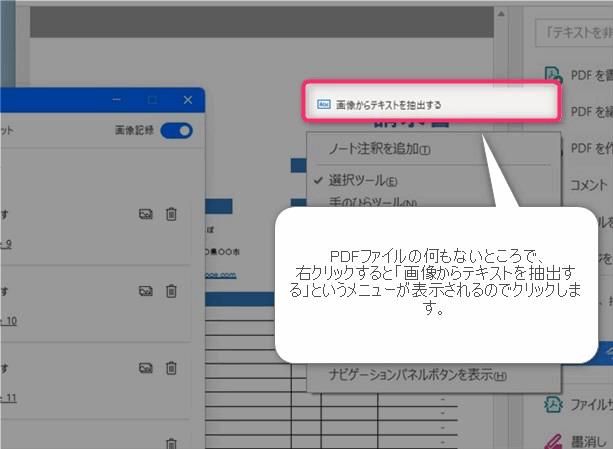
レコードを開始しましたら、先程ひらいたPDFを表示させて画面上で右クリックします。すると「画像からテキストを抽出する」というメニューが表示されますのでクリックします。

▲デスクトップ画面上に「1/2テキスト領域を定義する」というメッセージが表示されたことを確認します。
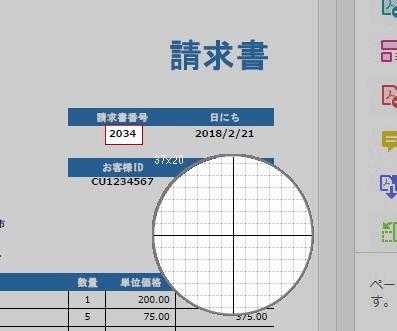
▲取得対象となる文字列部分をドラッグアンドドロップで囲みます。ここでは請求書番号を取得したいので「2034」の部分を囲みました。
テキスト領域とは、PDFから実際に取得したい文字列です!

▲デスクトップ画面上に「2/2アンカー領域を定義する」というメッセージが表示されたことを確認します。
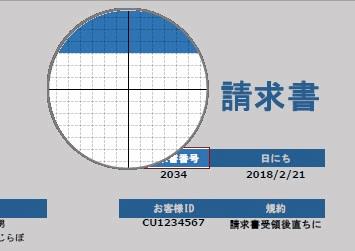
▲アンカー領域をドラッグアンドドロップで囲みます。アンカー領域とは、抽出する文字列の近くにある目印となる部分です。
今回の場合ですと「請求書番号」という文字列部分を囲んでアンカー領域としています。
何故「請求書番号」をアンカー領域にしたかといいますと、私が取得したいのは請求書番号である「2034」という文字列です。この数字は必ず「請求書番号」という文字列の下側にあります。目印として一番ちょうどいいかなと思うからです。
アンカー領域とは、PDFから実際に取得したい文字列の目印です!
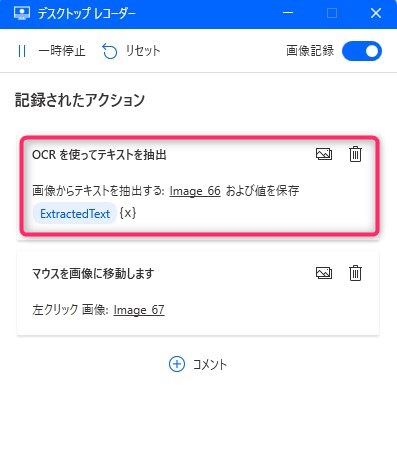
▲「テキスト領域」と「アンカー領域」の設定が完了すると「デスクトップレコーダー」画面に「OCRを使ってテキストを抽出」アクションが自動生成されます。
 じょじお
じょじおデスクトップレコーダーを使うとこのようにユーザの操作を元にアクションを自動生成してくれます。
▲「OCRを使ってテキストを抽出」アクションが「デスクトップレコーダー」画面に追加されたことを確認できたら、画面下の「終了」をクリックしてデスクトップレコーダーを閉じます。
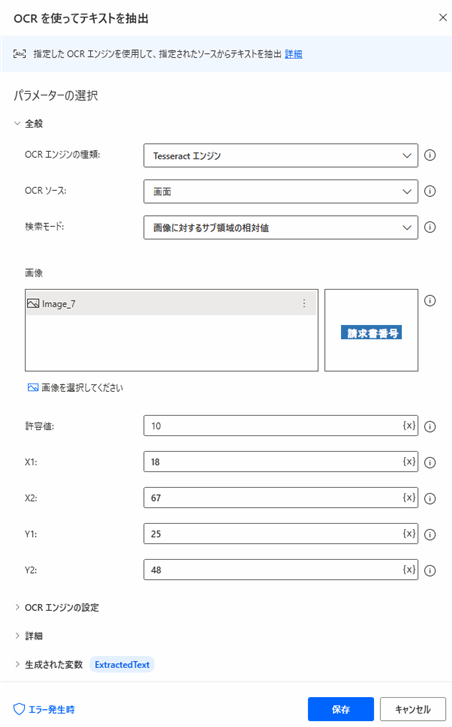
▲デスクトップレコーダーを閉じると、フローデザイナーに「OCRを使ってテキストを抽出」アクションが追加されます。アクションを開いて必要があればパラメータを調整しましょう。抽出対象が日本語の場合は言語コードを日本語にします。アンカー領域が日本語でも言語設定は英語で大丈夫です。日本語設定は下記リンクの前回の記事を参考にしてください。
今回は設定はこのまま次へ進みます。
OCRアクション実行後に開いたPDFファイルを閉じるために「ウィンドウを閉じる」アクションを追加します。「ウィンドウを閉じる」アクションは「UIオートメーション>Windows」のアクショングループにあります。
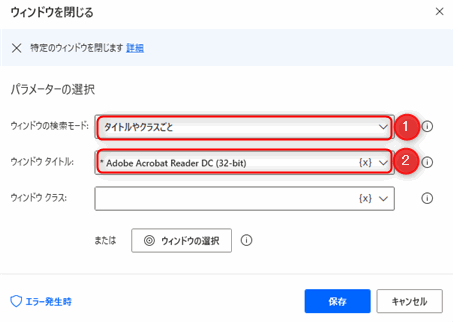
▲「ウインドウを閉じる」アクションのパラメータを入力します。
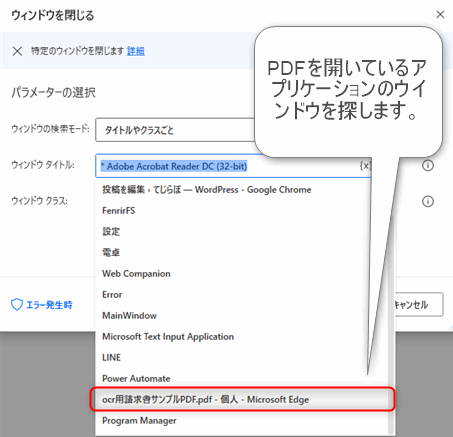
ウィンドウタイトルはPDFを開いているアプリケーションによってことなります。図はMicrosoft EdgeでPDFを開いた時の例です。
ウィンドウタイトルを選択したままの指定にするとファイル名が変わったときに動作しません。ループ処理の中で複数のPDFファイルを扱う場合にはワイルドカードである「*(アスタリスク)」を使って表現するといいです。たとえばMicrosoft Edgeの場合「* – Microsoft Edge」と指定するとどんなファイル名でもウィンドウを閉じることができます。
じょじお4つのアクションの追加が完成しました。
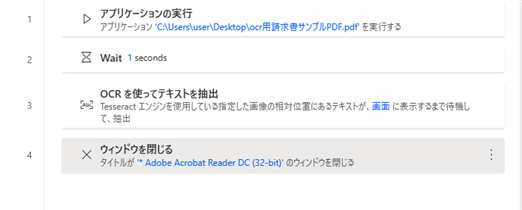
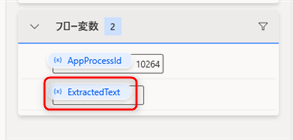
フローを実行してみましょう。ExtractedText変数に抽出結果が出力されます。フロー変数一覧に表示されているExtractedText変数をダブルクリックして中身を確認してみましょう。
PDFを開くアクションは前回開いた時のウィンドウサイズと開いた位置を記憶しています。例えばPDFを画面の右下に小さく開いてから閉じてアクションを実行すると同じように右下に小さく開きます。今度は最大化して閉じてからアクションを実行すると、PDFが最大化の状態で開きます。
こういう挙動があるのでファイルを開くたびに「OCRを使ってテキストを抽出」アクションに指定している座標が変わってしまって失敗することがあります。
このため、常にウィンドウを最大化して開くようにした方が良いかもしれません。ウィンドウを最大化するには「キーの送信」アクションを使ってウィンドウを最大化するショートカットキー「Windowsキー+↑」を送信すると良いかと思います。
じょじお以上、この記事では「OCRを使ってテキストを抽出」アクションを使ってPDFの文字列の一部を抽出する方法について解説しました。
▲Kindleと紙媒体両方提供されています。デスクトップフロー、クラウドフロー両方の解説がある書籍です。解説の割合としてはデスクトップフロー7割・クラウドフロー3割程度の比率となっています。両者の概要をざっくり理解するのにオススメです。
▲Power Automate for Desktopの基本をしっかり学習するのにオススメです。この本の一番のメリットはデモWebシステム・デモ業務アプリを実際に使ってハンズオン形式で学習できる点です。本と同じシステム・アプリを使って学習できるので、本と自分の環境の違いによる「よく分からないエラー」で無駄に躓いて挫折してしまう可能性が低いです。この点でPower Automate for desktopの一冊目のテキストとしてオススメします。著者は日本屈指のRPAエンジニア集団である『ロボ研』さんです。
▲Power Automate クラウドフローの入門書です。初心者の方には図解も多く一番わかりやすいかと個人的に思っています。
Microsoft 365/ Power Automate / Power Platform / Google Apps Script…
▲Udemyで数少ないPower Automateクラウドフローを主題にした講座です。セール時は90%OFF(1200円~2000円弱)の価格になります。頻繁にセールを実施しているので絶対にセール時に購入してくださいね。満足がいかなければ返金保証制度がありますので安心してご購入いただけます。



