ガチなシャツ
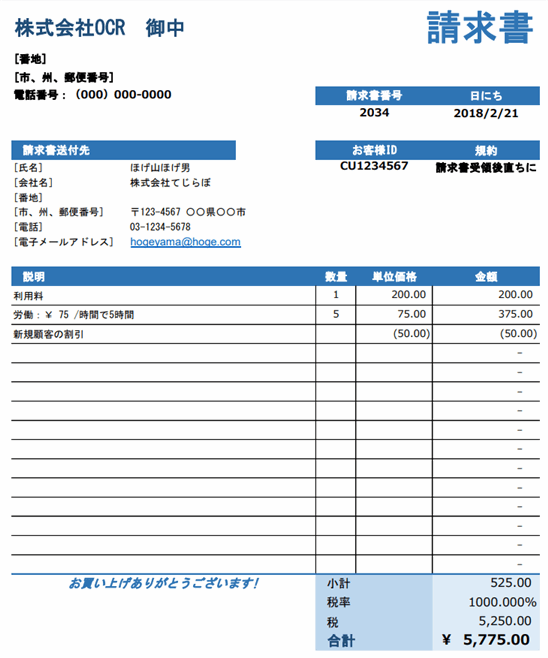
【2026年版】リライブシャツを実際に着た感想|現行モデルの違い・デメリット・注意点旧モデルを実際に購入した筆者が、2026年の通常版・プレミアム・β・コアの違い、価格、デメリット、α自主回収、Amazon購入時の注意を正直に解説します。

 じょじお
じょじおWindows11から標準搭載された無料RPAツールPower Automate for desktopの「PDFからテキストを抽出する」アクションを試してみました。

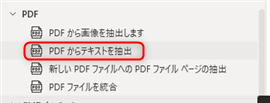
▲「PDFからテキストを抽出」アクションはPDFグループの中にあります。ドラッグアンドドロップで追加します。
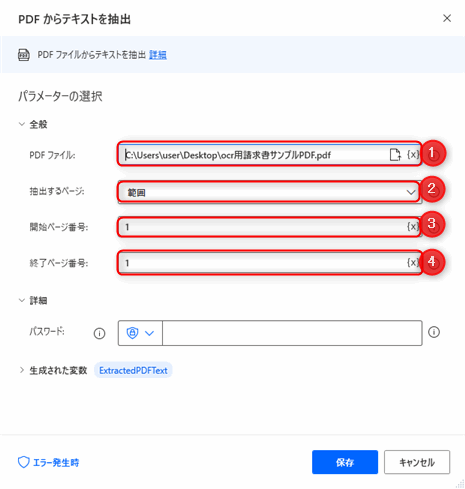 じょじお
じょじおとりあえず抽出するだけでしたら以上のワンアクションでできちゃいます。次のステップでフローを実行してみましょう。
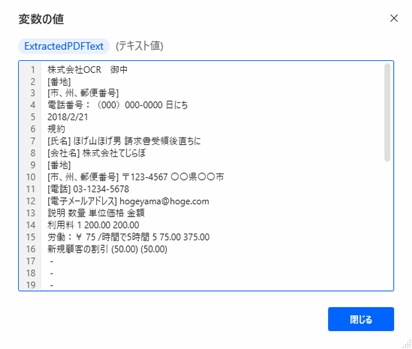
▲フローを実行するとExtractedPDFText変数に抽出結果が格納されます。変数ペイン>フロー変数>の中のExtractedPDFText変数をダブルクリックすると中身を確認できます(上図)。
今回のPDFでは割と正確に情報をとれました。しかし、PDF操作全般に言えることですが文字抽出は完璧ではありませんので人の眼によるチェックは必要かなと思います。
とりあえずすべてのテキスト抽出はできましたが、取得した文字をそのまますべて使うというケースはあまりないかと思います。実際の業務では例えば「金額」「」

▲文字列操作系のアクションで文字列を抽出する方法は下記の記事で解説しています。よろしかったら参考になさってください。

▲正規表現を使った文字列抽出についてはこちらの記事で解説しています。よろしかったら参考になさってください。
画像を抽出するには「PDFから画像を抽出する」アクションを使用します。
>>「PDFから画像を抽出する」アクションを使用する方法はこちら(記事作成中)
じょじお以上、この記事では「PDFからテキストを抽出」アクションの使い方について解説しました。
 ぽこがみさま
ぽこがみさまこのブログではRPA・ノーコードツール・VBA/GAS/Pythonを使った業務効率化などについて発信しています。
参考になりましたらブックマーク登録お願いします!
▲Kindleと紙媒体両方提供されています。デスクトップフロー、クラウドフロー両方の解説がある書籍です。解説の割合としてはデスクトップフロー7割・クラウドフロー3割程度の比率となっています。両者の概要をざっくり理解するのにオススメです。
▲Power Automate for Desktopの基本をしっかり学習するのにオススメです。この本の一番のメリットはデモWebシステム・デモ業務アプリを実際に使ってハンズオン形式で学習できる点です。本と同じシステム・アプリを使って学習できるので、本と自分の環境の違いによる「よく分からないエラー」で無駄に躓いて挫折してしまう可能性が低いです。この点でPower Automate for desktopの一冊目のテキストとしてオススメします。著者は日本屈指のRPAエンジニア集団である『ロボ研』さんです。
▲Power Automate クラウドフローの入門書です。初心者の方には図解も多く一番わかりやすいかと個人的に思っています。
Microsoft 365/ Power Automate / Power Platform / Google Apps Script…
▲Udemyで数少ないPower Automateクラウドフローを主題にした講座です。セール時は90%OFF(1200円~2000円弱)の価格になります。頻繁にセールを実施しているので絶対にセール時に購入してくださいね。満足がいかなければ返金保証制度がありますので安心してご購入いただけます。



